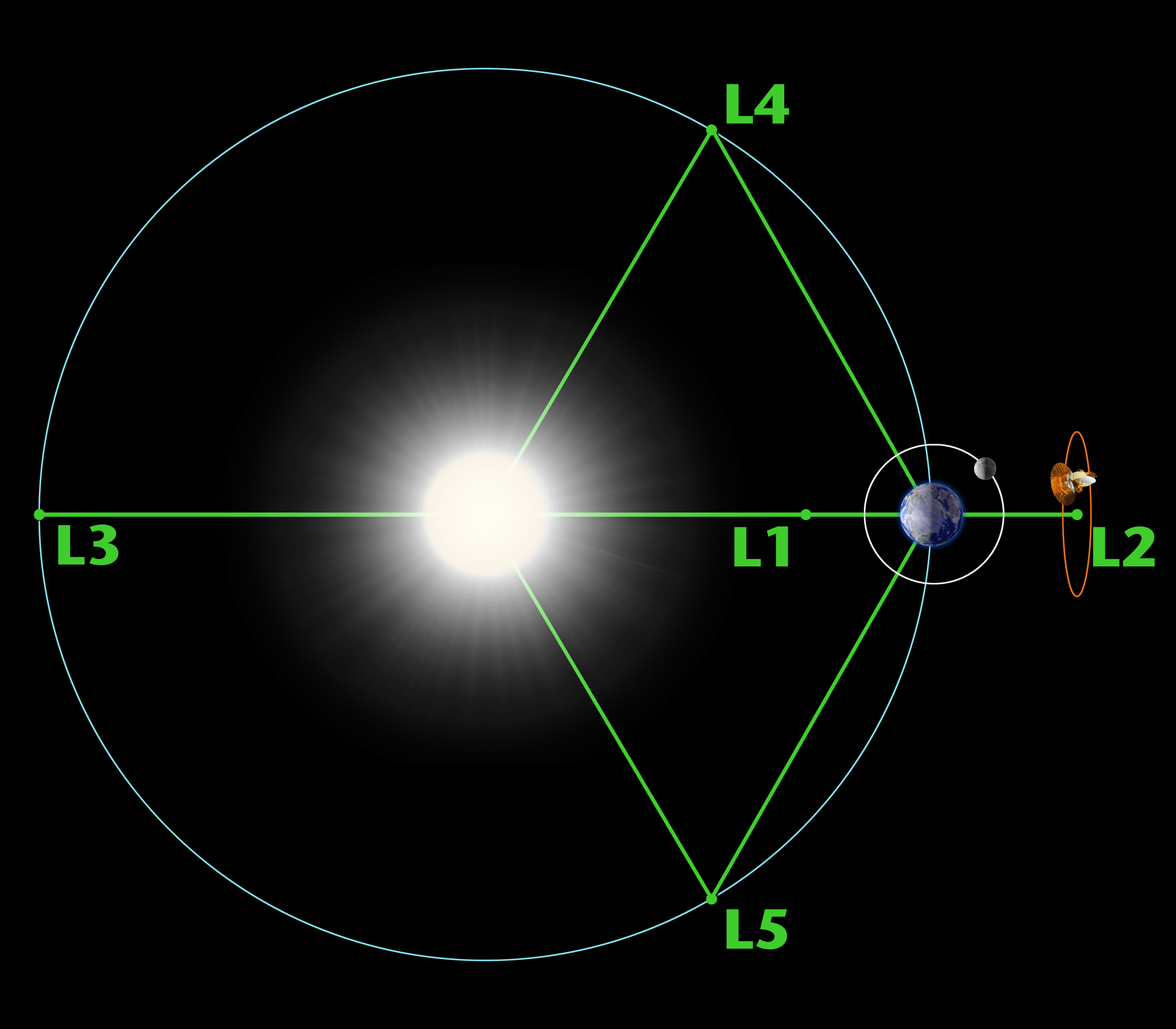
So my coworker Charlie had a million dollar idea;
Charlie - "What if there was a light that would turn on when your drives are accessed?!"
me - "Like on a floppy, or a CD drive, or the HDD LED on a tower case? 'cause those exist."
Charlie - "Yeah, but what if you have more than one hard drive? You can't tell which drive is being accessed."
me - ..... [speechless because this never occurred to me.]
Charlie went on to describe a youtube video by Barnacules Nerdgasm in which he mines the WBEMTest for disk BytesPerSec. Barnacules even writes a task tray program that blinks an icon when there is drive activity.
So anyway, the Barnacules source code is available;
Download HDDLED Source Code @ http://bit.ly/hddledsource
But it still has a single indicator for multiple drives.
This is where the NeoPixel comes in. It is an addressable RGB LED from Adafruit. https://www.adafruit.com/product/1463

By editing the Barnacules code each LED can flash in sync with each drive. My edit of his code is linked below.
Still one more missing piece, an Arduino to control the NeoPixels. While Adafruit has some good options (like the feather and the itsy bitsy https://www.adafruit.com/product/3677), I have some even smaller 32u4 based arduino clones.
 |
| On ebay search for 32u4 beetle. |
Right click on the icon to open the window. Select the com port of the Beetle. close the window to make it go back to the tray.


The arduino IDE serial monitor (115200) can be used to control the LEDs directly.
I created a simple protocol that will change the RGB values, save the current setting to the eeprom, and load a setting from the eeprom.

type ? and hit enter to get the command list.
Bonus fact:
The 16 LED neopixel ring fits perfectly inside of a 25.5 to 46 mm step up filter adapter. I use this combination as a cheap RGB ring light for Fujinon and Edmund Optics c mount lenses.
Links:
Link to the video tutorial that creates the hard drive monitor windows task bar program:
https://youtu.be/NO_gqbE3e54
Link to the windows DiskInUse.exe program (the tray icon program). [You need to download all 5 files]:
https://drive.google.com/drive/folders/1D6-6OxUc0U8kgMIwfBFOwcCH4KyNw9Rm
Link to the Arduino NeoPixel program for the beetle:
https://drive.google.com/drive/folders/1rrfyhyyoC2KdOJnyA5NroIgqLb55Yq_m
Make sure you load the adafruit neopixel library in the arduino IDE.
This is the full project file that includes my edits of Barnecules' code:
https://drive.google.com/drive/folders/13CgYQedi1gVSaGxQgzgVjCNX0y1hNcYT
The following screen captures are just here to help me remember the location of the data. You don't need to access this, but it is amazing how much can be accessed from the OS.

 |
| click Connect when it opens. |

 |
| when connected click enum Classes |
 |
| select Recursive then OK |
 |
| win32_PerfFormattedData_PerfDisk_PhysicalDisk |
 |
| DiskBytesPersec |